
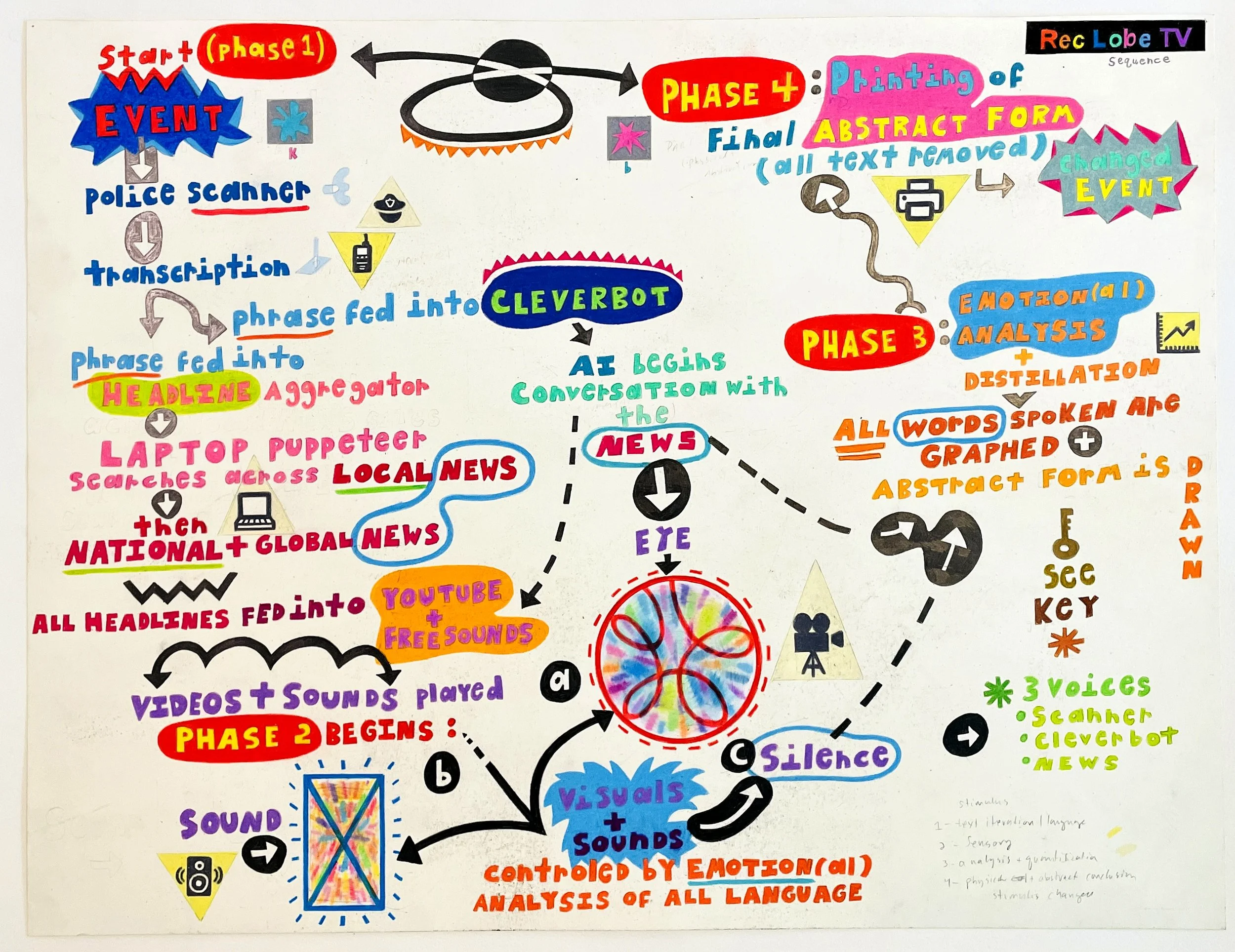
Sequence Diagram
colored pencil and graphite on paper, 22 x 30”
Video and Installation Views
Materials: Police Scanner, Projection, Laptop, Speakers, Sound, Printer, Printouts
















University of Wyoming Art Museum
July 2 thru December 22, 2022
CONCEPT>> Rec Lobe TV maps the labyrinthine processes through which human experience is perceived and transformed - from observation through language - into a multi-sensory simulacrum that affects consequent behavior and beliefs. RLTV follows this chain reaction step-by-step, rendering the results visible, no matter how bizarre: from real-time accounts of local events and national news reporting, into the untethered time-space of the internet and AI intelligence. Like mapping a complex, multi-directional game of telephone, RLTV mirrors the process by which we come to believe what’s real in the world, as direct observation of a singular phenomenon mutates through law enforcement, media, AI, stochastic stimuli, and storytelling into eerily uncanny phenomena. Like Joseph Heller wrote in Catch-22, “Just because you’re paranoid, doesn't mean they aren’t after you.”
PRESS RELEASE EXCERPT>> Bringing together real time events, collaged footage, global patterns of journalistic story-telling, chatbot AI, and appropriated human commentary, Rec Lobe TV portrays several ‘intelligences’ attempting to make sense of each other and the world at large. In ways both fascinating and terrifying, the slippages that perpetually dislodge any emergent logic send us down the rabbit hole. Each output (projection, graphs, media, web browsing) represents a specific method through which we, as human beings, attempt to understand the world via the media around us, and, simultaneously, how these same media cycles can confuse, obfuscate, and ultimately cause us to lose our senses of self. While there are parameters within which RLTV operates, our collective forfeits a significant degree of agency to the system we create, embracing the unpredictable at each step, as the moment-to-moment outcome cannot be anticipated. Simultaneously humanistic and technological, Rec LobeTV advances our investigation of the uncanny entities that shape our lives.
SEQUENCE
PHASE ONE
EVENT (occurs somewhere in Laramie)
Unknown to us, somewhere in the local community, an event occurs. This might be physical or emotional, or mundane or consequential. It may or may not have a concrete relationship to what’s simultaneously happening somewhere else in the world.
POLICE SCANNER (back left of gallery on table)
The first evidence of direct observation. An observer calls in to report the event and this language begins the chain reaction of iterative communication. The words used by the dispatcher or officer give linguistic form to the event, which originally occurred independent of language. This is the first iteration of our “story.”
TRANSCRIPTION (visible on monitor positioned back left)
As the police scanner is played audibly, our system listens and attempts to transcribe the words and noises it hears into language. This is the first instance of human interaction with a device or machine. The computer’s interpretation of language is often full of errors. This is the next step in the mutation of language away from the original phenomenon and into a new, yet uncanny replica.
NEWS HEADLINE API (visible on monitor / national headline projected on graph at outset of each sequence)
Our invented headline API searches this transcribed language across news sites. It begins with LOCAL NEWS headlines and ranks headline similarity according to language similarity. The most similar headline is isolated and searched across NATIONAL NEWS sources. This headline serves as the first input into the sensory transformations that form the project’s main projections and sounds (primarily Youtube & Freesound). Although no news headline could possibly have been describing a hyper local event that occurred in real time, this phase represents the ways in which similarity - how we might hear about something, search for it on the web, and find a story that seems related - can flatten time and space and move nonlinearly away from the original event. Select HEADLINES are visible on the monitor, analyzed for emotional potency, and projected prominently on the central projection.
CLEVERBOT (visible as scrolling white text in graphing projection and intermittently on the laptop)
The same headlines are fed into the AI chatbot, Cleverbot. This initiates the AI conversation with the news / live events. Cleverbot attempts to make sense of the transcribed phrase, and draws from its vast memory of past conversations with human beings in an attempt to respond as a human might. This conversation is charted on the graph for its emotional qualities (see graph phase below) and Cleverbot continues to speak to itself until another transcription or news headline interrupts its conversation. Like a spinning top, Cleverbot’s conversation meanders in unpredictable directions as a conscious person might talk to themselves while pondering some subject. Words spoken by Cleverbot and the emotion classifications of what it says are also fed into the Youtube and Freesound phase of the project (see below).
LAPTOP (back left, on table)
A laptop’s scale is human and familiar, and its screen is our most commonly used window into the virtual world. RLTV’s laptop displays various aspects of the project's machinations: data input, transcription feed, automatically updated news pages. Visitors can see our project “think,” so to speak, on the laptop.
PHASE 2
YOUTUBE (projected on right wall)
All language – transcription, each news headline, Cleverbot’s phrases – will be fed into Youtube. Videos that result from these searches will be projected in a circular “eye-like” form. This eye will move across the wall, shrink and grow in circumference, and speed up and slow down, all according to our emotional analysis of the words spoken. Its visual effects (blurriness, color saturation, contrast, playback speed, etc.) are also manipulated by the emotions of the words, as if what it’s saying, hearing, or reading is affecting it emotionally and psychologically. Do we search more frantically when we’re angry or scared, or do we linger and slowly zoom into an image or video when we’re calm and happy?
This generative light and motion phase is the first example of the newly transformed sensory output of our RLTV sequence. While there is some language in the videos and sounds, its main focus is on the light, color, and motion of the projected videos, which, because of our manipulations, often morph into pure abstraction. We rarely see videos in this way: when the videos blur, they become pure sensation of light and color, devoid of language.
The roving eye also bridges the temporal aspects of the exhibition’s space with our AI component. The eye could be the computer looking at human media for meaning or to understand - like an alien coming to earth. Or it might be us - humans examining ourselves as a method of self-reflection.
The scale of the projection is cinematic and bodily, feeling like a movie or film, which dwarfs the human body. As each video ends, the next video will play, pulling the project / sequence down the rabbit hole. This is not unlike how someone might find conspiracy theory videos after watching videos of games or the news.
SOUND (speakers positioned around space)
The same language is fed into the free-sound online database. These sounds will graft onto the videos, creating dissonance between what visitors see and what they hear. The sounds, collected on freesound.org have been uploaded by people online, and are available for free. By searching RLTV’s phrases across this database, we’re bridging the language of news with the descriptive tags added by users. This bridge will likely be tenuous, but keeps the consequential sequence going.
SILENCE (intermittent)
At various intervals in the exhibition, RLTV will go silent. Nothing will be audible other than the ambient sounds of the exhibition space. During these moments, visitors will become acutely aware of the sounds of their immediate environment. Like when a television commercial goes quiet, we look up and pay attention. These moments are tangible interruptions, pulling visitors out of the virtual and into an observable, temporal reality, much like the original event was “real.”
PHASE 3
GRAPH (projected on center wall)
Projected on the far wall is a sentiment analysis graph we’ve developed. It evolves as the conversation progresses. This graph maps the words spoken and color codes them according to their emotion classification. It also records emotional dissonance, which is a crucial indicator that the data the system is encountering is alarmingly incongruous, causing it to become confused. This is akin to the experience, when we encounter something unfamiliar, we may feel uncomfortable, fearful, or even elated because we don’t yet know how to categorize or even describe what we’ve encountered. The graph plots each phrase as coordinates on a grid and connects them into a shape as it progresses. This shape represents the abstract culmination of the entire process. This graphing process is akin to an ongoing, simultaneous self-analysis, as when we act on an impulse and then attempt to understand why. It’s a cognitive phase; not sensory, bodily, or physical. Until it prints - then it becomes pure material.
PHASE 4
PRINTED SHAPE (back of gallery)
The final phase of each sequence is an automatically printed abstraction (the graph’s final form sans data). This physical printout will be the only tangible evidence of Rec Lobe TV’s transformation of physical experience into language, and back into the physical and sensory. Visitors can hold and even take this piece of paper with them. The initial event has become something new. The shape may be abstract and devoid of language, yet it’s highly specific, as it could only have resulted from the peculiarities of that particular sequence. The shape crystallizes the arc of the system into form, and will never be replicated in the same way.